안녕하세요~ 오늘의 5분개발지식라디오! 오늘은 일반적으로는 잘 쓰이지 않는 고급 자바스크립트 문법을 배워보려고 합니다. 어떤 개념인지, 어떤 용도로 쓸 수 있을지를 한번 이야기해보도록 하겠습니다. Proxy에 대한 설명과 예제, 그리고 어떻게 사용할 수 있을지까지 쭉 달려볼 예정이니 끝까지 시청해주세요~
먼저 단어의 어원을 알아보겠습니다. Proxy라는 단어의 번역을 보면 “대리”라는 뜻입니다. 단어의 뜻과 동일하게 proxy는 어떠한 객체를 “대리”하는 역할을 합니다.
Proxy를 어떠한 객체에 대해서 생성을 하면 타겟 객체의 속성에 대한 읽기, 쓰기 등을 대리해서 먼저 처리할 수 있습니다. 코드를 보면서 이야기하는 것이 더 빠를 것 같습니다.
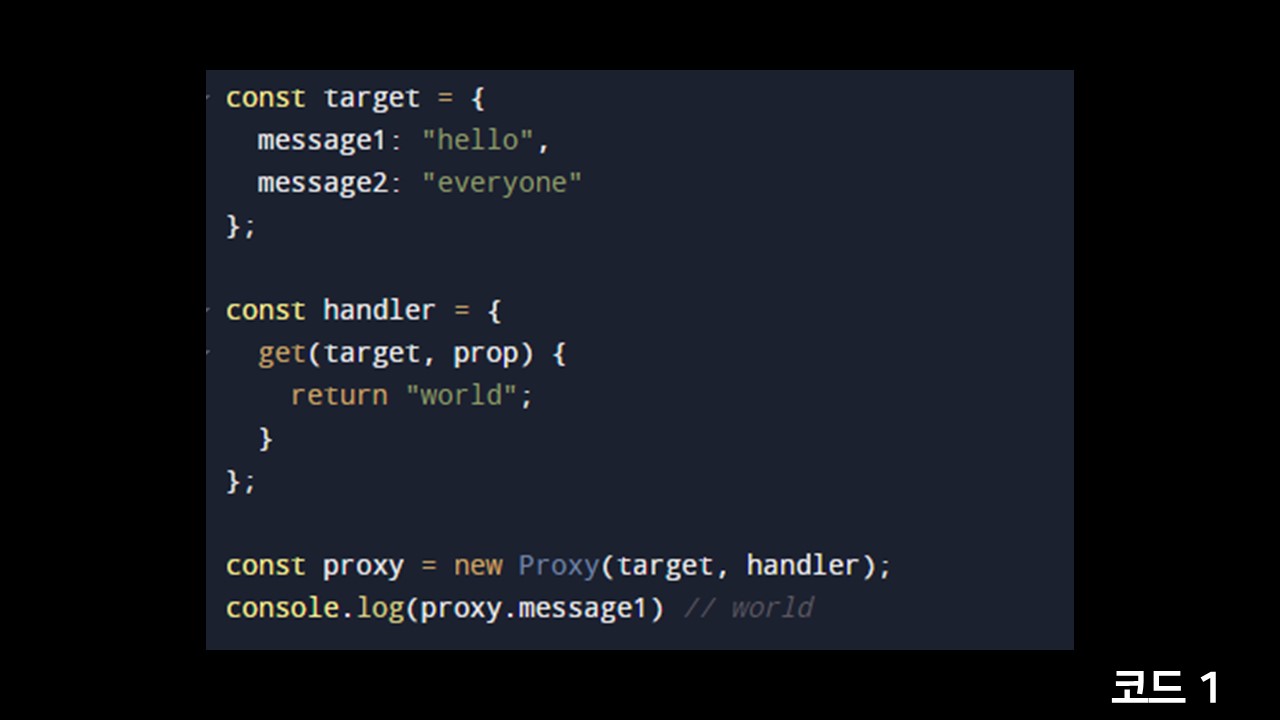
위쪽의 target과 handler를 지나쳐서 프록시를 생성하는 부분을 먼저 보겠습니다. new Proxy를 해서 프록시 객체를 생성할 수 있고, 첫번째 인자로는 프록시할 대상인 타겟 객체, 두번재 인자로는 해당 객체에 오는 요청 중 가로채서 대신할 동작들을 재정의한 메소드로 가지고 있는 handler, 공식용어로는 트랩을 넘겨줍니다.
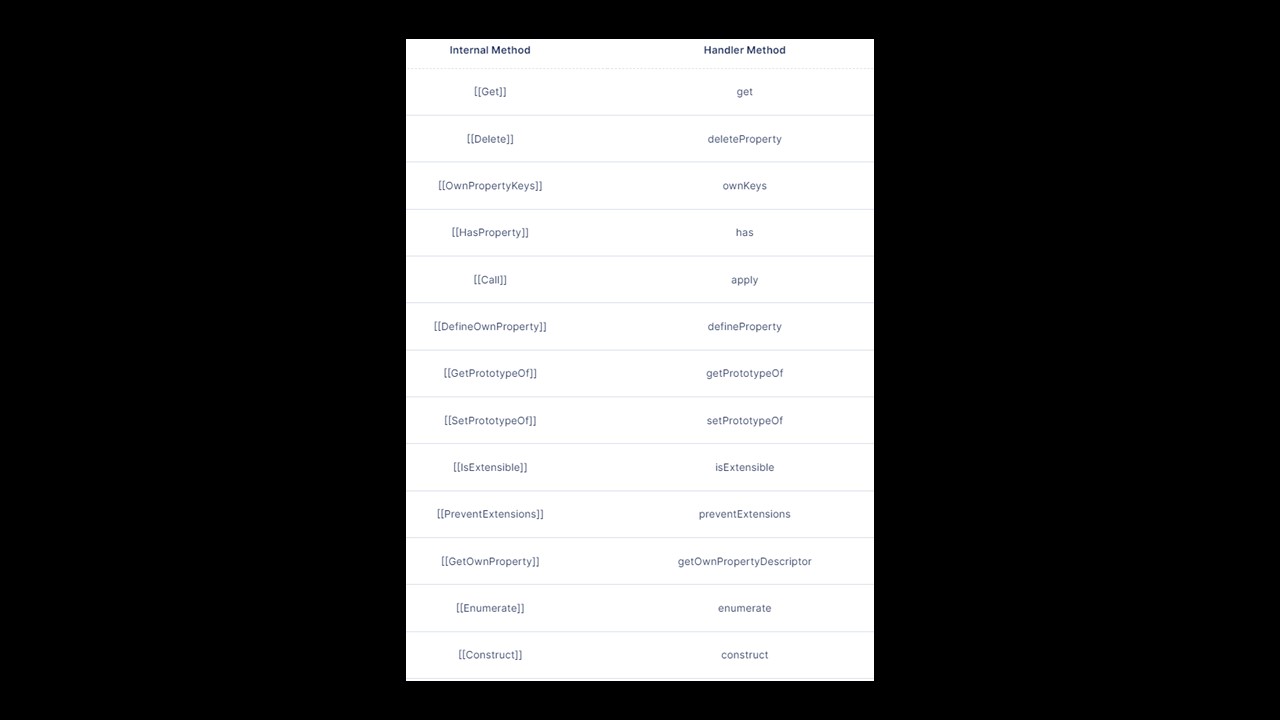
두번째인자인 핸들러의 경우 이미 약속된 이름의 메소드들을 재정의해야됩니다. 가장 일반적으로 쓰일만한 get, set, has, apply들이 먼저 눈에 띕니다. 개발하시면서 가로채고 싶은 동작들을 선택적으로 불러다가 정의하면 됩니다.
그럼 다시 코드로 돌아오면 아까보다는 조금 더 이해가 되기 시작합니다. 우리는 target이라는 원본 객체를 프록시하기위해 proxy를 생성했습니다. 그리고 핸들러에는 get 동작을 가로채는 메소드를 추가했습니다. get메소드는 아무런 조건 없이 무조건적으로 world를 반환합니다.
그래서 마지막 줄의 콘솔로그를 보시면 proxy의 message1을 조회했지만 world가 찍히는 것을 보실 수 있습니다. 그럼 조금 더 복잡한 심화예제를 보도록 하겠습니다.
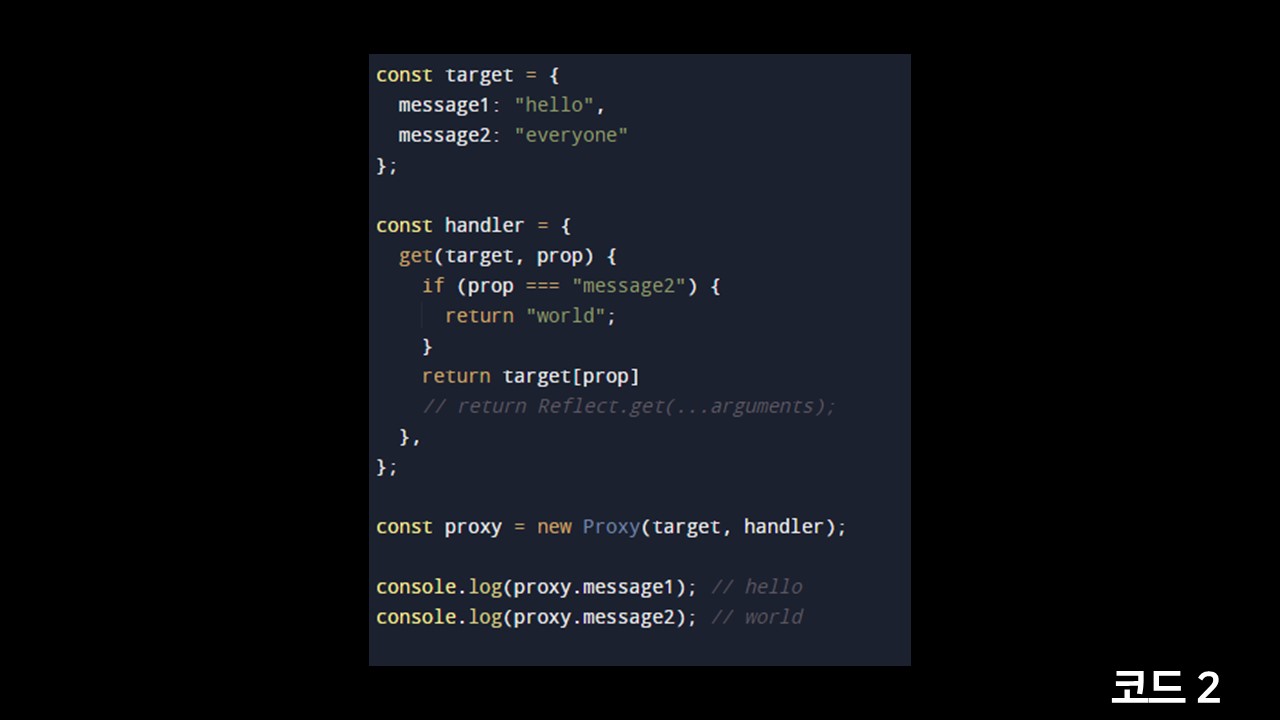
눈치가 빠르신 분들은 미리 파악하셨을수도 있지만 핸들러의 메소드들은 2가지 변수들을 인자로 받고 있습니다. 첫번째인자는 프록시의 원본 객체이고, 2번째는 코드가 접근하고 있는 속성의 이름을 줍니다. 따라서 현재 보이는 코드처럼 만약 message2를 접근할때는 world를 반환하고 나머지는 그대로 반환하도록 분기처리를 할 수 있습니다.

그래서 프록시는 간단하게 설명을 하자면 원본 객체 접근하기전에 가로채서 내마음대로 요청을 조작할 수 있는 객체인데요, 어떤 경우에 사용하게될까요? 사용방법은 무궁무진하지만 제가 공유드릴 유즈케이스는 유효성 검사, 데이터 싱크, 접근 제어입니다.
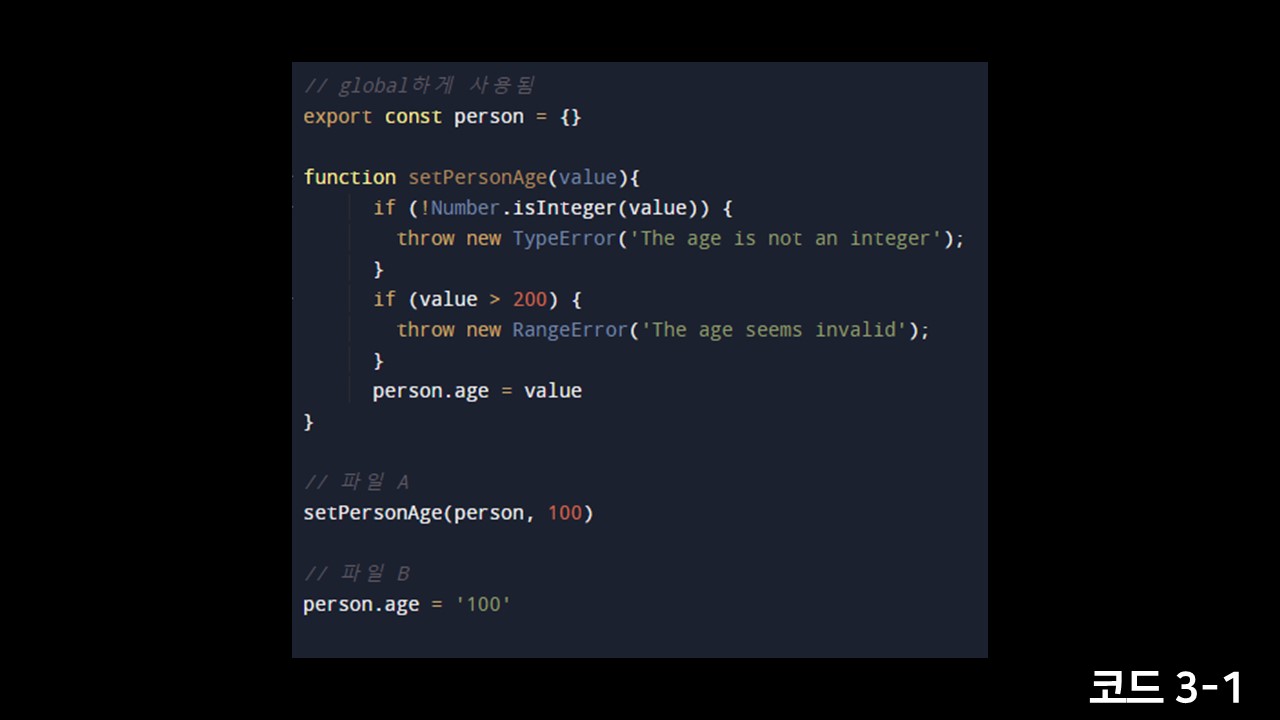
유효성 검사는 proxy에 대한 설명을 듣다보면 가장 먼저 떠오르는 유즈케이스입니다. 객체에 값이 쓰여질때 가로채서 validation을 통과하는지 확인할 수 있습니다. 코드를 보시죠:
자 공용으로 사용하는 person이라는 객체가 있다고 생각을 해보겠습니다. 이 객체는 여러 파일들에서 사용되고 있을때, person 객체에 age라는 속성을 세팅하려고 합니다. age는 나이이기때문에 정수타입으로 저장되고, 200살이 넘는 사람은 없기때문에 200이상을 에러를 내는 것이 타당합니다. 따라서 해당 조건들을 확인하는 setPersonAge라는 함수를 같이 작성해두었다고 하겠습니다.
팀으로 작업을하다보면 해당 함수의 존재를 알고 있는 사람도 있지만, 모르고 잇는 사람도 있을 수 있습니다. 아는 사람은 파일A처럼 잘 작성하였지만 setPersonAge라는 함수가 있는지도 모르고 정수로 저장되어야한다는 스펙도 모르는 사람은 파일B처럼 작성할 수도 있습니다. 파일B가 실행된 다음에는 person의 age를 참조하는 코드는 에러가 발생하겠죠.
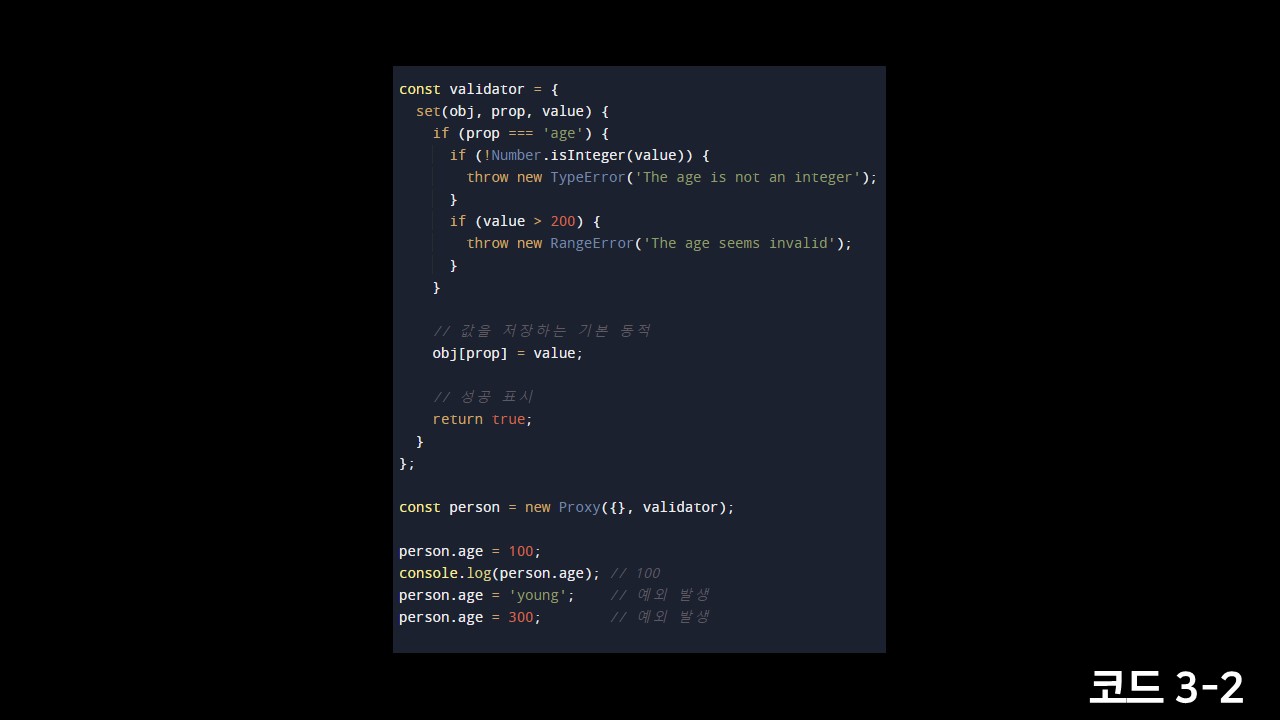
하지만 Proxy를 사용하면 근본적으로 set을 가로채서 유효성검사를 해버릴 수 있습니다. person은 빈객체를 원본객체로 인라인으로 넣어서 원본객체에는 접근이 불가능하도록 만들고 set을 가로챕니다. 그리고 age를 set하려고 하면 유효성검사를 진행하여 필요한 경우 에러를 뱉어줍니다.
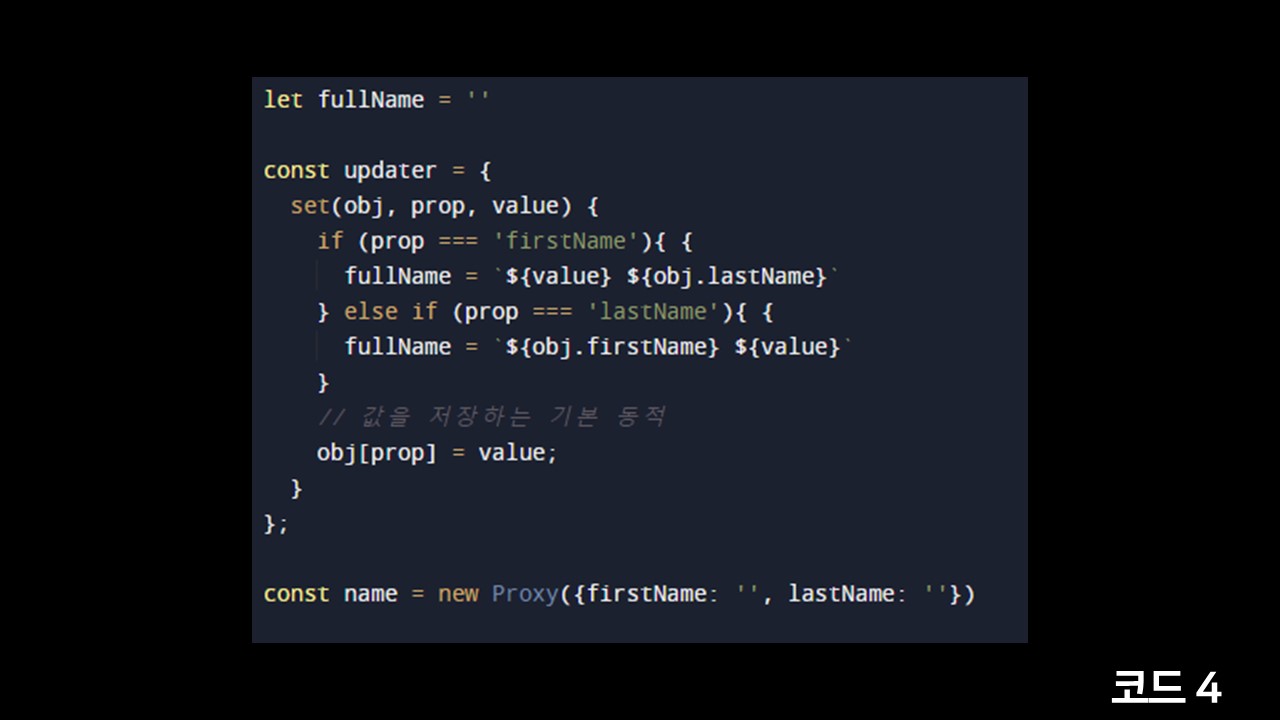
Proxy는 객체에 값이 변경될때 이를 알아챌 수 있습니다. 이 특징을 사용해서 연관된 다른 값들도 같이 업데이트를 하는 개념인데요, 간단한 예시를 보겠습니다.
가끔 프론트엔드 작업을 하시다보면 성과 이름을 입력받는 Input 태그가 분리되어있는 경우가 있습니다. 하지만 유저정보를 수정하거나 생성할때는 이 두개의 값을 합쳐서 하나의 문자열로 보내야되는 경우가 있을 수 있습니다.
이런 경우 name이라는 객체에 firstName과 lastName 속성이 업데이트될때 어딘가에 있는 fullName을 같이 업데이트해줄 수 있습니다. 물론 나중에가서 필요할때 합치는 것이 어렵지는 않지만 개념적으로 이해하시면 좋을 것 같습니다. 본 예시처럼 하나의 데이터의 변화를 어딘가에 싱크를 맞춰줘야되는 경우 사용할 수 있습니다. 마치 react의 useEffect를 사용해서 싱크해주는 것과 비슷합니다.

Proxy는 속성에 접근할때 이를 가로채고 미리 확인할 수 있습니다. 따라서 사용자가 접근 가능한 속성들을 미리 선언해두고, 이 리스트에 없을 경우 임의로 다른 값을 내려주는 것도 가능합니다.
코드를 보시면 age가 아닌 다른 속성에 접근하려고 하면 ‘ACCESS-DENIED’를 내려줘서 막습니다. 이전에는 특정 속성에 접근하지 못하게 하기 위해 메소드를 통해서만 속성들을 내려주거나 변수명에 특정 기호를 붙여 private 변수임을 명시했는데요, proxy를 사용하면 이를 원천적으로 차단할수도 있습니다.
자 오늘은 여기까지해서 Proxy에 대해서 알아보았는데요, 영상을 찍다보니 좀 길어졌네요 ㅎㅎ 무궁무진한 사용방법들이 있겠지만 간단하게 느낌을 잡기에는 이 정도면 충분한 것 같습니다. 다른 참신한 사용법이 잇다면 댓글에 공유해주세요
오늘도 같이 공부해주셔서 감사합니다. 유용했다면 구독 좋아요 부탁드립니다.
끝!
'프론트엔드' 카테고리의 다른 글
| React 신규 기능: Server Component (0) | 2023.04.30 |
|---|---|
| 차세대 React 렌더링 방식: React Suspense (0) | 2023.04.30 |
| React 13 변경점 중요한 것만 빠르게 짚어보기 (1) | 2023.04.26 |
| Rendering pipeline 쉽게 이해하기 (0) | 2023.04.26 |
| Debounce vs Throttling 이해하기 (0) | 2023.04.26 |

개발자_무형